인덱스는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조입니다.
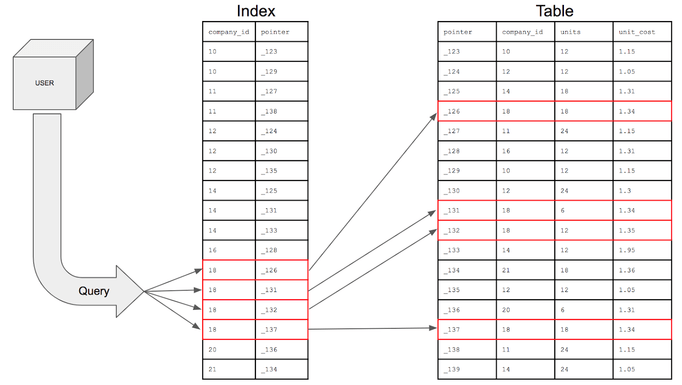
개념
인덱스는 위 사진에서 볼 수 있듯이 Table의 1개 혹은 여러개의 컬럼을 Key로 삼고, 해당 Key의 물리적인 주소값을 저장해 둡니다. 흔히 인덱스를 책의 색인과 비유하곤 하는데 우리가 책의 내용중 특정 내용을 찾기위해 책 전체 내용을 보는것은 비효율 적입니다. 그래서 맨뒤 혹은 맨 앞에 저자들이 색인을 추가해 주는데 데이터베이스의 색인 기능이 바로 Index입니다.
장점
- 인덱스는 데이터의 주소값을 갖고 있다.
- 주소값을 통해 원하는 값을 빠르게 찾을 수 있다.
- 시스템의 부하를 줄일 수 있다.
단점
- 정렬된 상태의 유지. -> INSERT, UPDATE, DELETE를 통해 데이터가 추가되거나 값이 바뀐다면 Index 테이블의 값들을 다시 정렬해야 합니다. 즉, 원본 테이블과 Index 테이블 두군데에 데이터 수정 작업이 필요합니다.
- 인덱스 관리를 위한 자원 필요 -> 인덱스 테이블을 수정하고 관리할 인력과 시간이 필요합니다.
- 추가적인 저장공간 사용 -> 인덱스 테이블을 만들어야 하기 때문에 10%~30%의 저장공간이 필요합니다.
인덱스를 사용하기 좋은 상황
- INSERT, UPDATE, DELETE가 자주 발생하지 않을때.
- JOIN / WHERE / ORDER BY를 자주 사용할때
- 혹은 데이터의 중복도가 낮은 컬럼 등이 있습니다.
인덱스를 생성할 때는 다음과 같은 사항들을 고려해야 합니다.
- 어떤 컬럼에 인덱스를 걸 것인가?
인덱스를 걸어서 빠른 검색을 하고자 하는 컬럼을 선택해야 합니다. 보통은 검색이 자주 일어나는 컬럼이나 조건절에서 자주 사용되는 컬럼에 인덱스를 걸어주는 것이 좋습니다.
- 어떤 종류의 인덱스를 사용할 것인가?
B-Tree 인덱스는 가장 일반적으로 사용되는 인덱스로, 대부분의 DBMS에서 기본적으로 제공됩니다. 하지만 특정 상황에서는 다른 종류의 인덱스를 사용해야 할 수도 있습니다. 예를 들어, 텍스트 검색을 위해서는 Full-Text 인덱스를 사용하는 것이 더 효율적일 수 있습니다.